과적합
과적합은 학습한 모델이 학습 데이터에만 과도화게 최적화되어 실제 예측으로 다른 데이터를 사용할 때 예측 성능이 과도하게 떨어지는 것을 말합니다. 이를 해결하기 위해 교차검증을 이용하여 다양한 학습과 평가를 수행해서 이를 해결합니다.
k 폴드 교차 검증 => KFold
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
dt_clf = DecisionTreeClassifier(random_state=156)
# n_splits=5 로 5개의 폴드 데이터 세트로 분리합니다.
kfold = KFold(n_splits=5, shuffle=True)
# 5개의 폴드 세트로 분리하는 KFold 객체와 세트별 정확도를 담을 리스트 객체 생성
cv_accuracy = []
n_iter = 0
# kfold.split( ) 으로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터를 추출합니다.
for train_index, test_index in kfold.split(iris.data):
x_train, x_test = iris.data[train_index], iris.data[test_index]
y_train, y_test = iris.target[train_index], iris.target[test_index]
# 학습 및 예측
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
n_iter += 1
# 반복할 때 마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('\n#{} 교차검증정확도:{}, 학습데이터 크기:{}, 검증데이터 크기:{}'.format(n_iter, accuracy, train_size, test_size))
print('#{} 검증세트인덱스:{}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
print('\n## 평균 검증 정확도:', np.mean(cv_accuracy))

k 폴드 교차 검증 => Stratified K
Stratified K 폴드는 불균형한 분포도를 가진 레이블 데이터 집합을 위한 방식입니다.
import pandas as pd
iris = load_iris()
# 데이터 프레임으로 만들어줍니다.
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 레이블에 타겟 번호를 넣어줍니다.
iris_df['label'] = iris.target

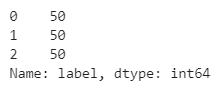
# 붓꽃 데이터 분포도 확인
iris_df['label'].value_counts( )
# Stratified K 모듈을 불러옵니다.
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits=3)
n_iter = 0
for train_index, test_index in kfold.split(iris_df, iris_df['label']):
n_iter += 1
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print('## 교차검증:{}'.format(n_iter))
print('학습 레이블 데이터 분포:\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_test.value_counts())
# 붓꽃 데이터는 비율이 같지만, 만약 비율이 한쪽으로 쏠려 있어도 골고루 뽑아낼 수 있습니다.

dt_clf = DecisionTreeClassifier(random_state=156)
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
for train_index, test_index in skfold.split(iris.data, iris.target):
x_train, x_test = iris.data[train_index], iris.data[test_index]
y_train, y_test = iris.target[train_index], iris.target[test_index]
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('\n#{} 교차검증정확도:{}, 학습데이터 크기:{}, 검증데이터 크기:{}'.format(n_iter, accuracy, train_size, test_size))
print('#{} 검증세트인덱스:{}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
print('\n## 평균 검증 정확도:', np.mean(cv_accuracy))

'파이썬(Python)' 카테고리의 다른 글
| 파이썬 머신러닝 기본1 (0) | 2021.08.10 |
|---|---|
| 판다스 / pandas 4 - 데이터 병합(merge, concat) (0) | 2021.08.06 |
| 판다스 / pandas 3 - 정렬, 컬럼제거, 데이터 가공, 파생변수 생성 (0) | 2021.08.06 |
| 판다스 / pandas 2 - 데이터 추출(인덱싱, 슬라이싱, loc, iloc, 불리언 인덱싱) (0) | 2021.08.05 |
| 판다스 / pandas 1 - 기본생성, 외부에서 데이터 호출, 데이터 기본 점검 (0) | 2021.08.04 |



