- 데이터 준비 -
pandas 정렬 => .sort_values
.sort_values(by = '컬럼명', ascending = False or True)
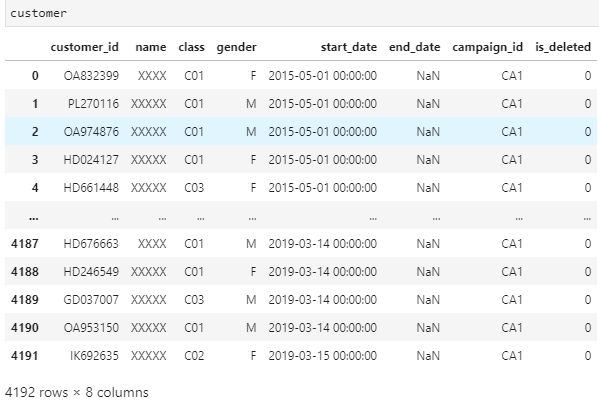
customer.sort_values(by = 'is_deleted', ascending = False)
# ascending : 오름차순

pandas 컬럼 제거 => drop
.drop
customer1 = customer.drop(['end_date'], axis = 1)
customer1

데이터 가공 => apply
- 데이터 준비 -
df = pd.DataFrame([
[1,2,3,4],
[7,6,9,2]
])
df

def cal(col):
return col.max()- col.min()
df.apply(cal)
# col에는 컬럼별로 배열이 들어옵니다.

cal(np.array([1,2,6,9,11,15]))
# 15-1 = 14

df[0].apply(lambda x : x*2)

파생변수 생성
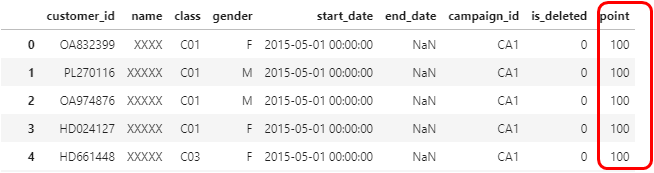
customer['point'] = 100
customer
np.zeros((4192, ), dtype=np.int32) + 101
customer['point'] = np.zeros((4192, ), dtype=np.int32) + 101
customer

'파이썬(Python)' 카테고리의 다른 글
| 파이썬 머신러닝 기본1 (0) | 2021.08.10 |
|---|---|
| 판다스 / pandas 4 - 데이터 병합(merge, concat) (0) | 2021.08.06 |
| 판다스 / pandas 2 - 데이터 추출(인덱싱, 슬라이싱, loc, iloc, 불리언 인덱싱) (0) | 2021.08.05 |
| 판다스 / pandas 1 - 기본생성, 외부에서 데이터 호출, 데이터 기본 점검 (0) | 2021.08.04 |
| 넘파이 / numpy 5 - 선형대수, 저장 및 로드, 압축 (0) | 2021.08.04 |



