파이썬 머신러닝에 들어가기 전에 pc에 anacoda가 설치되어있어야 합니다.
아나콘다 설치 방법은 아래 링크를 참고해주세요.
https://developer-notes.tistory.com/2
아나콘다 설치 / Anaconda install
이 글에서는 아타콘다 설치방법과 주피터랩 실행을 설명하였습니다. 도움이 되었다면 좋아요와 구독버튼을 눌러주세요. 아타콘다 홈페이지 접속 https://www.anaconda.com/products/individual Anaconda | Indi
developer-notes.tistory.com
iris 데이터 불러오기 및 확인
import numpy as np
import pandas as pd
# 사이킷런(scikit) : 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리입니다.
from sklearn.model_selection import train_test_split
# 사이킷런에 내장되어 있는 붓꽃 데이터를 불러옵니다.
# sklearn.datasets : 서아캇론에서 자체적으로 제공하는 데이터 세트를 생성하는 모듈입니다.
from sklearn.datasets import load_iris
iris = load_iris()
iris

iris.keys()

# iris의 key 중 target_names과 feature_names의 속성을 알아봅니다.
iris.target_names

feature_names

# 판다스를 사용하여 iris 데이터를 데이터프레임 형태로 만들수 있습니다.
import pandas as pd
iris_df = pd.DataFrame(data = iris.data, columns=iris.feature_names)
iris_df
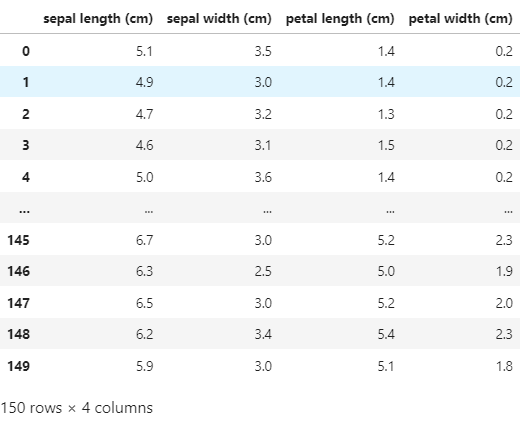
# 새로운 label 컬럼 추가, label은 붓꽃의 종류를 0 1 2로 구분한 것입니다.
# sklearn.tree : 트리 기반 ML 알고리즘 구현한 클래스 모입입니다.
iris_df['label'] = iris.target
iris_df.sample(3)

# sklearn.model_selection : 학습 데이터와 검증 데이터 그리고 예측 데이터를 분리하거나 최적의 하이퍼 파라미터로 평가하기 위한 다양한 모듈의 모입니다.
* 하이퍼파라미터 : 하이퍼 파라미터는 모델링할 때 사용자가 직접 세팅해주는 값을 뜻합니다.
from sklearn.model_selection import train_test_split
train_test_split(iris.data, iris.target, test_size=0.2, random_state=11)
# train_test_split(x, y) 에서 x는 독립변수이고 y는 종속변수 입니다.
# test_size=0.2 는 테스트 데이터를 20%로 지정하는 것입니다.
# random_state 는 랜덤값을 고정하기 위해 사용하였습니다.
# 즉, X_train의 독립변수와 Y_train 종속변수롤 학습을 하고 / X_test 독립변수와 Y_test 종속변수로 학습한 것을 기반으로 테스트 하는 것입니다.
X_train, X_test, Y_train, Y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=11)
머신러닝 학습시키기
분류는 데이터가 구분지어져 있을 때 사용합니다.
회귀는 데이터가 연속적으로 이어져 있을 때 사용합니다.
# 의사결정 트리 클래스를 결정합니다.
# iris데이터는 분류데이터이므로 DecisionTreeClassifier를 사용합니다.
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=11)
# 학습일 시킵니다.
dt_clf.fit(X_train, Y_train)
# 예측을 해봅니다.pred = dt_clf.predict(X_test)
pred

# 예측한 값과 닶을 비교해봅니다.
Y_test

# 정답확인을 좀 더 쉽게하기 위해서 'accuracy_score' 을 사용합니다.
from sklearn.metrics import accuracy_score
accuracy_score(Y_test, pred)

# 93.3333 의 정확도를 가집니다.
임의의 값으로 붓꽃 데이터를 확인해보기
dt_clf.predict([[5.6, 3.2, 4.7, 1.4]])

# sepal length (5.6) / sepal width (3.2) / petal length (4.7) / petal width (1.4) 를 넣었더니 1번 붓꽃이라고 결과가 도출되었습니다.
정리
# sklearn에 있는 붓꽃 데이터를 가져옵니다.
from sklearn.datasets import load_iris
# 분류기준을 선택합니다.
from sklearn.tree import DecisionTreeClassifier
# 정확도를 체크하기 위한 모듈을 준비합니다
from sklearn.metrics import accuracy_score
# 붓꽃 데이터를 가져옵니다.
iris = load_iris()
# 붓꽃 데이터를 분류하기 위한 틀을 만듭니다.
dt_clf = DecisionTreeClassifier()
# 붓꽃 데이터를 학습시킵니다.
dt_clf.fit(iris.data, iris.target)
# 붓꽃을 예측합니다.
pred = dt_clf.predict(iris.data)
# 결과를 확인합니다.
accuracy_score(iris.target, pred)
# 결과는 100%가 나오며 이유는 이미 학습한 학습 데이터 세트를 기반으로 예측했기 때문입니다
# 때문에 학습 / 테스트 데이터를 분리하여야 합니다.
dt_clf = DecisionTreeClassifier()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
accuracy_score(y_test, pred)
'파이썬(Python)' 카테고리의 다른 글
| 파이썬 머신러닝 기본 2 (0) | 2021.08.11 |
|---|---|
| 판다스 / pandas 4 - 데이터 병합(merge, concat) (0) | 2021.08.06 |
| 판다스 / pandas 3 - 정렬, 컬럼제거, 데이터 가공, 파생변수 생성 (0) | 2021.08.06 |
| 판다스 / pandas 2 - 데이터 추출(인덱싱, 슬라이싱, loc, iloc, 불리언 인덱싱) (0) | 2021.08.05 |
| 판다스 / pandas 1 - 기본생성, 외부에서 데이터 호출, 데이터 기본 점검 (0) | 2021.08.04 |



